Introduction
Some time ago at work, I was tasked with loading an image from S3 to render it onto a canvas. However, a CORS error popped up, causing the image to not display. After a long debugging journey, I finally solved the issue and wrote an article about it on Medium. When I was about to copy that article here, I stumbled upon Huli’s excellent CORS Complete Guide, and realized my knowledge of CORS was pretty shallow. After digesting more information and doing extra research, I decided to rewrite and supplement my original content to make it more complete.
If you want the best CORS tutorial, please refer to Huli’s articles. This post will focus on the topic discussed in Part 6 of the series: CORS Issues That May Not Be CORS Issues”.
What Problem Did I Encounter?
As shown below, the goal was to display a user-selected image on a <canvas> in the frontend. When users switch the image on the left, the image in the <canvas> updates accordingly.

To render the image onto the <canvas>, you must set crossorigin to anonymous when loading the image:
1 | const img = new Image(); |
Let me quickly explain why we need to set crossorigin to anonymous. Feel free to skip if you already know.
A Quick Explanation
Browsers enforce the Same-Origin Policy: two pages have the same origin if their protocol, domain, and port are all identical; if any one differs, they are of different origins.
This policy limits cross-origin resource sharing, preventing malicious sites from accessing sensitive data without the user’s consent. For example, without it, a malicious site could use cookies from your logged-in bank session to steal your account data.
A common misunderstanding: when requesting cross-origin resources, the browser still sends the request; only upon receiving the response does the browser block access to it (for JavaScript), due to the Same-Origin Policy.
To make cross-origin HTTP requests, browsers use CORS (Cross-Origin Resource Sharing), which is essentially a protocol using HTTP request and response headers.
When a cross-origin request is made, the browser automatically adds an Origin header, indicating the source website:
1 | Origin: https://your-website.com |
If the server approves, it responds with an Access-Control-Allow-Origin header, either with a specific origin or * to allow all origins:
1 | Access-Control-Allow-Origin: https://your-website.com // Allow only a specific origin |
The browser will then compare Access-Control-Allow-Origin with the page’s current Origin. If they match, JavaScript can access the resource. Otherwise, the browser blocks it and throws a CORS error.
There are several types of cross-origin requests: simple requests, preflight requests, credentialed requests, etc., each requiring different headers. Failure to comply results in CORS errors.
You might wonder: images loaded via the browser are also cross-origin—why don’t they trigger CORS errors?
1 | <img src="https://other-website.com/image.png" /> |
This is because the Same-Origin Policy mainly restricts JavaScript’s access to the contents of cross-origin resources, not the loading of them via HTML tags like <img>, <script>, <link>, etc. These tags are intended to display or execute resources, but do not expose their content to JavaScript.
However, if you draw any cross-origin image onto a canvas without proper CORS permission, the canvas becomes “tainted”. Once tainted, any JavaScript methods that try to read the pixel data will be blocked with a SecurityError, including:
canvas.toDataURL()canvas.toBlob()ctx.getImageData()
For example:
1 | ctx.drawImage(img, 0, 0); // This works, draws the image |
Therefore, to load an image that can be used on canvas without tainting, you usually set crossorigin to anonymous. (MDN reference)
In this mode, the browser makes a CORS request without sending any identifying info like cookies, auth headers, or TLS client certificates. To the server, it looks like an anonymous, unrelated visitor. If the server returns the resource under these conditions, it means it’s public and not sensitive to who’s requesting it.
So, the server can safely respond with Access-Control-Allow-Origin: *—this tells the browser that any origin’s JavaScript can access the resource. The browser, seeing this, happily lets JS read the resource.
Back to the Main Story
So, my expectation: by setting img.crossOrigin = "anonymous", the response from the server would include Access-Control-Allow-Origin: *, letting me draw the image on the canvas.
However, the response headers were empty, and a familiar CORS error appeared in the console. Even stranger: sometimes the error appeared, sometimes not, making debugging very uncertain.
1 | Access to image at “<url-path>” from origin ‘http://localhost:3000' has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource. |
Since the image was stored in S3, I suspected S3’s CORS policy was misconfigured. But upon inspection, everything seemed fine—AllowedMethods included GET, and AllowedOrigins was set to *:
1 | [ |
Maybe S3 is configured correctly but the headers aren’t reaching me? I tested using curl:
1 | curl -I -H "Origin: http://localhost:3000" <url-path> |
And the response did include the expected header:
1 | HTTP/1.1 200 OK |
So, the browser should be receiving the correct response headers—but for some reason, it wasn’t using them.
Is Caching to Blame?
Looking back at the failed request in the Network tab, I noticed a warning under the request headers:
Provisional headers are shown. Learn more
The linked explanation says:
Sometimes the Headers tab shows the Provisional headers are shown… warning message. This may be due to the following reasons:
- The request wasn’t sent over the network but was served from a local cache, which doesn’t store the original request headers. In this case, you can disable caching to see the full request headers.
This means: the request wasn’t actually sent, but was served from cache. Somewhere, an identical image URL had been loaded before, and cached by the browser—but the cache does not store the original request headers. The next time the image is loaded, the browser grabs it from cache—but the cache lacks the CORS headers, so a CORS error occurs.
A closer look at my page revealed the key: the left image is loaded via a style attribute, while the right side uses <canvas>:
1 | <div style={{ background: `url(<url-path>)` }}></div> |
Loading the image with CSS (or an <img> tag) is an anonymous request—it doesn’t trigger a CORS request, so no Origin header is sent, and the server doesn’t include Access-Control-Allow-Origin: * in its response. That response is cached. Later, when JavaScript loads the image for the canvas using new Image(), the browser reuses the cached image, but the cache lacks the necessary CORS header—so a CORS error occurs.
When I enabled “Disable cache” in the Network tab, the CORS error disappeared—confirming my suspicion.
But why does the browser do this?
Even if there’s a cached resource, shouldn’t the browser ignore it if the CORS headers are missing? Otherwise, using cache will always cause CORS errors for cross-origin requests!
After some searching, I discovered people have been discussing this issue since at least 2012:
- CORS policy on cached Image
- Cross-origin request from cache failing after regular request is cached.
The answer from @chromium.org in the second thread:
This is simply how HTTP caching works. Most resources do not look at most headers, so HTTP, by default, does not incorporate headers into the cache key. If it did, every browser update would clear the HTTP cache (User-Agent header changes), and you wouldn’t get caching across different kinds of fetches (Accept header changes).
In other words, HTTP caching by default does not include request headers in the cache key. If it did, every change in headers like User-Agent or Accept would cause caches to be missed, reducing cache efficiency.
So, using a cache entry created without CORS headers for a later CORS request is not a bug—it’s a design for efficiency.
The solution: servers should include a Vary: Origin header in responses.
Thus, if the server sends us responses without Vary: Origin, it has told us that the response is not sensitive to the Origin field. The HTTP cache is thus free to reuse the request when it adds the Origin header. The fix is straightforward: if the server looks at the Origin header (or lack thereof), it must send Vary: Origin.
According to MDN on the Vary header:
Including a Vary header ensures that responses are separately cached based on the headers listed in the Vary field. Most often, this is used to create a cache key when content negotiation is in use.
Content negotiation is an HTTP mechanism for choosing the best representation of a resource, like language selection via Accept-Language. If the cache key doesn’t include this header, you might get the wrong version.
With Vary: Accept-Language, the browser knows to keep separate cache entries for each language. Similarly, Vary: Origin ensures that responses to requests with/without the Origin header are cached separately.
Did This Solve My Problem?
Not quite. Here’s why: Amazon S3.
Is Amazon S3 to Blame?
As mentioned above, if the server always returns Vary: Origin for a resource, everything works. The catch: S3 only returns Vary: Origin when a CORS request is made, not for regular requests.
Consider this workflow:
- The image is first loaded via CSS, with no
Originheader. S3 responds withoutVary: Origin. The browser caches the response, not associating it withOrigin. - Later, JavaScript loads the image with
crossOrigin = "anonymous", triggering a CORS request. The browser checks the cache. Since the previous response lackedVary: Origin, it assumes the cache is valid regardless of headers, and serves the cached image (which lacksAccess-Control-Allow-Origin), causing a CORS error.
This is how S3 behaves—it only returns Vary: Origin for CORS requests. This behavior has led to multiple WontFix bugs in Chrome:
- XHR CORS requests for images fail when image previously loaded via img tag
- Cross-origin request from cache failing after regular request is cached.
- Amazon S3 CORS implementation primes cache to reject cross-origin requests
The root issue is not the browser’s lack of intelligence, but that S3 (as the server) does not always provide the crucial Vary: Origin cache hint.
Should S3 Provide the Vary Header?
Let’s check RFC 7231, Section 7.1.4:
An origin server SHOULD send a Vary header field when its algorithm for selecting a representation varies based on aspects of the request message other than the method and request target, …
Meaning: if the server’s choice of response varies based on certain request headers (other than the method or URL), it should include a Vary header.
Applied here: if the presence of an Origin header causes the server to return different responses (CORS or not), then it should include Vary: Origin in all responses.
However, as this answer points out, RFC only says “SHOULD” (recommended), not “MUST” (required), so S3’s omission is not technically a violation.
So: Chrome and S3 are both standards-compliant—but the standards themselves have a gap.
Solutions
This answer suggests three possible solutions:
Recommended: Lambda@Edge Solution
First, some background: Amazon CloudFront is a popular CDN used with S3, caching resources worldwide. Lambda@Edge extends AWS Lambda functions to CloudFront edge nodes, letting you execute code in response to CDN events.
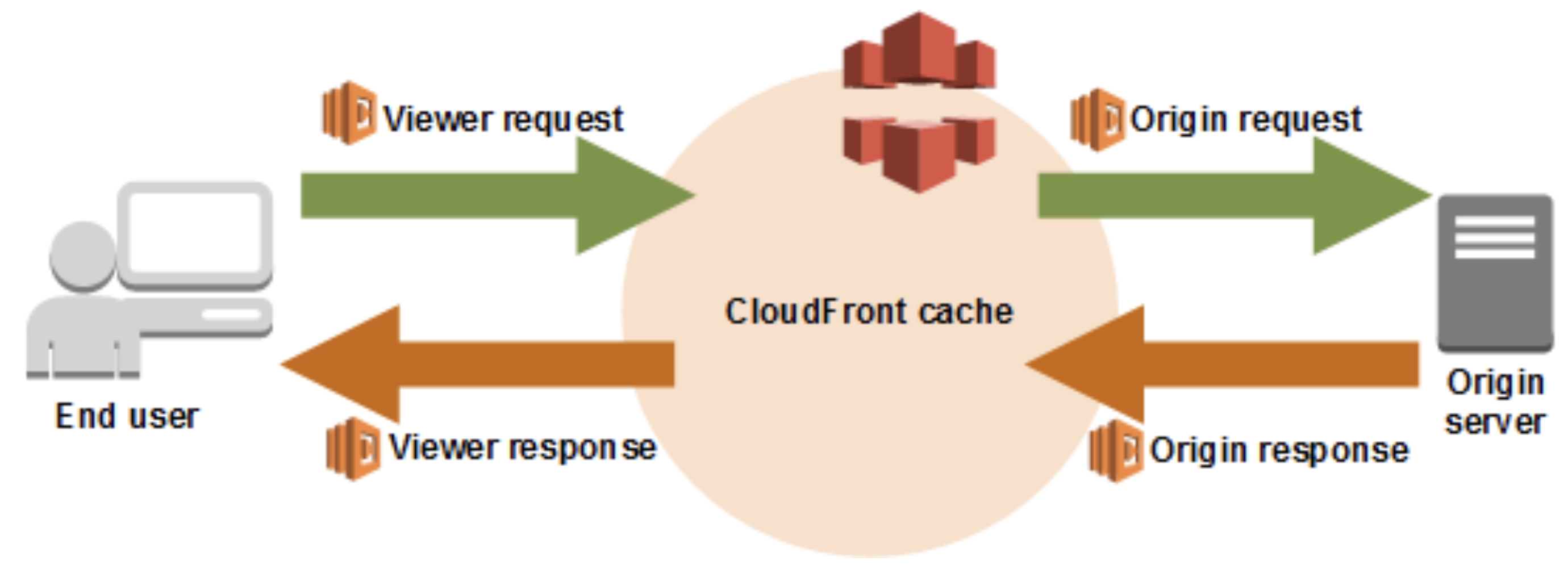
CloudFront supports Lambda@Edge triggers on:
- Viewer Request (before checking the cache)
- Origin Request (before contacting the origin server, e.g., S3)
- Origin Response (after receiving response from origin, before caching)
- Viewer Response (before returning to the browser)
The suggested approach: add a Lambda@Edge function on the Origin Response event. If the response lacks a Vary header, add:
1 | Vary: Access-Control-Request-Headers, Access-Control-Request-Method, Origin |
This guarantees the browser/cache will correctly separate CORS and non-CORS responses.
Alternative 1: Inject a Fake Origin Header via CloudFront
Another approach is to add an Origin header on all Origin Requests via CloudFront, so that S3 always returns a response with Vary: Origin. (See AWS Docs)
However, this makes all requests look like CORS requests, possibly affecting cache efficiency.
Alternative 2: Use Dummy Query String Parameters
The simplest (but also most brute-force) solution: append a dummy query string parameter to the URL, forcing the browser to treat them as different resources and skip cache.
For example, use one parameter for the HTML/CSS image:
1 | <img src="https://example.com/image.png?_ctx=html" /> |
And another for the JavaScript CORS request (as long as it’s different):
1 | img.src = "https://example.com/image.png?_ctx=cors"; |
The browser sees these as different URLs and fetches both anew.
This is a form of cache busting—by changing the resource URL, you ensure the cache doesn’t interfere.
What Did I End Up Doing?
Under time pressure, I went with the brute-force approach: adding a dummy query parameter.
Since the only place in our website needing CORS access was when loading images for canvas, I simply appended ?_canvas=1 to those URLs.
With that, the CORS error was finally resolved.
Summary of the Problem
To summarize, the root causes are:
- Browser HTTP caching does not include request headers in cache keys.
- S3 only returns
Vary: Originfor CORS requests. - As a result, browsers may incorrectly serve cached responses without the required CORS headers, leading to errors.
If you just need a quick fix, adding a dummy query string parameter is the simplest way out.
Let me know if you want further edits or formatting tweaks!
Comments